

In the mobile and embedded market, the design constraints of electronic products can sometimes be seen as tight and contradictory: the market demands higher performance yet lower power consumption, reductions in cost but shorter time-to-market.
These constraints have created a trend for more specialized hardware designs that fit a particular application; if each task is well matched to a functional unit, fewer transistors are wasted and power efficiency is better. As a result, application processors have become increasingly heterogeneous over time, integrating multiple components into a single System-on-Chip (SoC).
The diagram below presents the architecture of a modern SoC. Such a chip typically includes a CPU (with optional multi-core and SIMD capabilities), a GPU for both 3D graphics acceleration and high-performance vector computation, an ISP (Image Signal Processor) for acquiring image sensor data, a VDE (Video Decoder and Encoder) for codec acceleration and an RPU (Radio Processing Unit) for connectivity. Each of these components has its own advantages and combinations of these can be used to implement many applications efficiently.
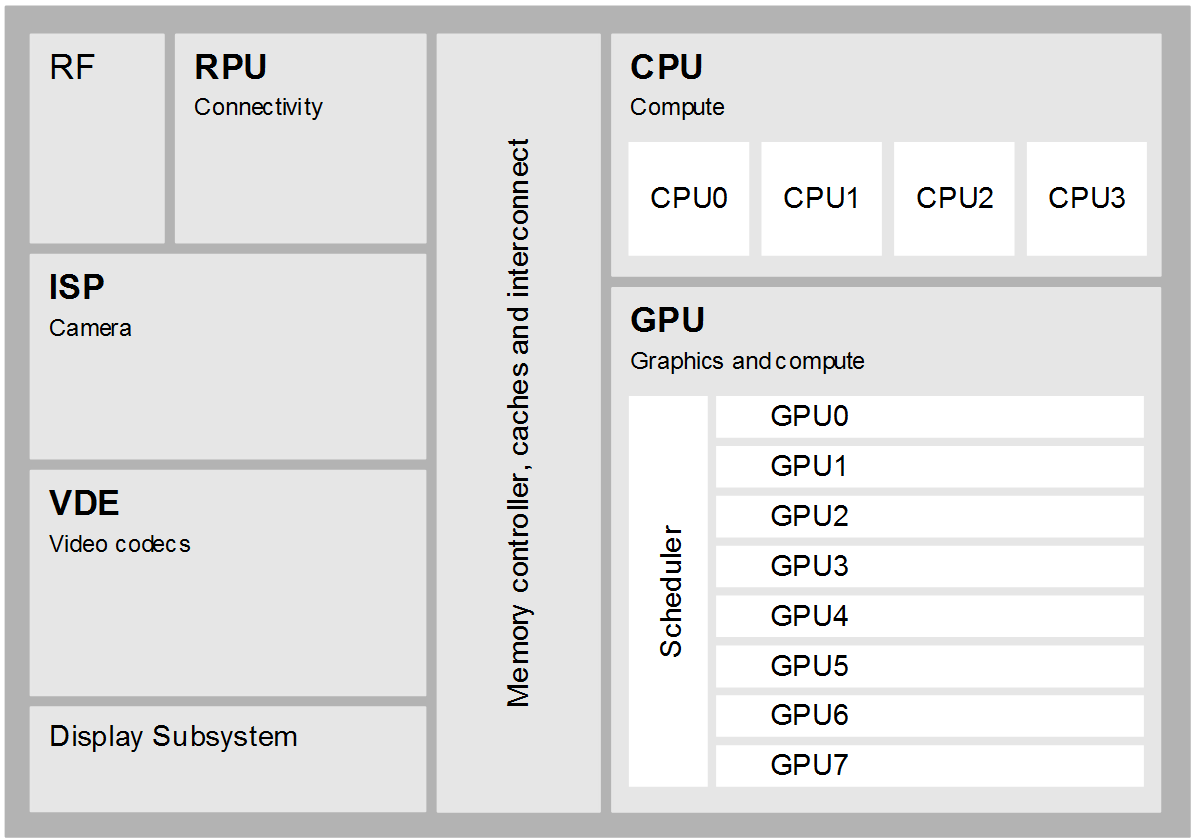
Today many application developers rely on the CPU to meet the requisite performance requirements of their advanced computational photography and computer vision algorithms. However, these CPU-centric solutions frequently struggle to deliver sustained video-rate processing of high-resolution images, largely due to thermal limits of the devices.
As shown in more detail in the figure below, a CPU combines a small number of cores with a large data cache, optimized for efficient execution of general-purpose control code with low memory latency. The GPU, on the other hand, dedicates its transistors to ALUs (arithmetic logic units) rather than data caches and control flow. This arrangement of hardware enables efficient execution of large unbranched data sets that require many repetitive arithmetic calculations, such as an image processing algorithm operating on many pixels.
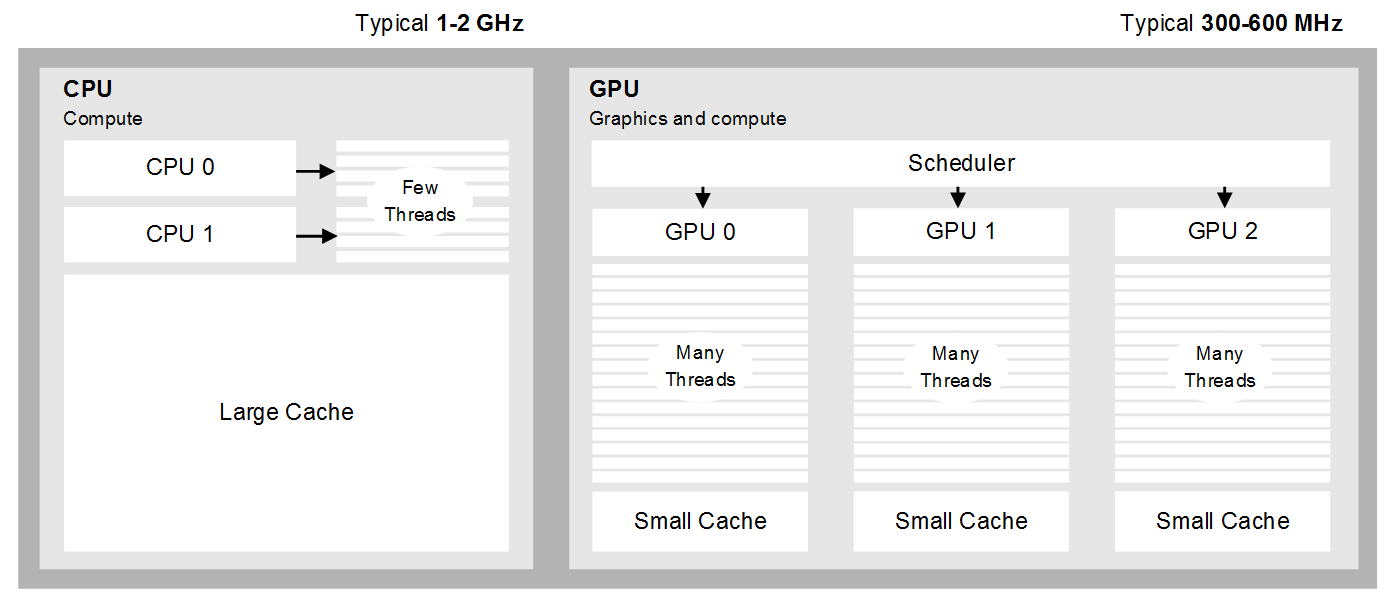
Furthermore, because the GPU is designed to run at lower clock speeds than a CPU, offloading image processing workloads from the CPU to GPU can lead to both an increase in performance and a reduction in power consumption and generated heat. The resulting implementation is also likely to be more balanced and also more responsive, as the CPU has more free cycles to respond to the demands of the operating system and user interface.
In the context of mobile and embedded software, heterogeneous computing is the process of combining different types of processing units together to meet an application’s performance requirements within a limited power and thermal budget. By partitioning the application into multiple workloads that can be distributed across the available hardware units, so that each workload is run on the hardware unit capable of executing it most efficiently, the overall performance and power-efficiency of the implementation can be improved.
When partitioning an application, serial tasks should usually be allocated to the CPU, whereas data-parallel tasks are good candidates for offloading to the GPU. If the SoC provides dedicated hardware accelerators such as an ISP or VDE, related tasks such as image de-noising and video playback should usually be allocated to these accelerators in order to maximise power-efficiency.
However, in some cases it may be desirable to implement these tasks in software instead, for example using GPU compute, to trade efficiency for a higher-quality algorithm than may be provided by the fixed-function accelerator. The use of GPU compute is particularly common in the field of computer vision where active research is continually leading to refinements of existing algorithms as well as entirely new vision algorithms. Fast deployment of these algorithms into products requires both programmability and a high-performance compute capability.
Join us next time for an example use case of heterogeneous computing and the existing bandwidth constraints SoCs currently face.
Please let us know if you have any feedback on the materials published on the blog and leave a comment on what you’d like to see next. Make sure you also follow us on Twitter (@ImaginationTech) for more news and announcements from Imagination.



