

After exploring a quick guide to writing OpenCL kernels for PowerVR Rogue GPUs and analyzing a heterogeneous compute case study focused on image convolution filtering, I am going to spend some time looking at how developers can measure the performance of their OpenCL kernels on PowerVR Rogue GPUs.
The performance of scalar code running on a CPU depends upon how fast the processor can execute the sequence of compiled instructions. In turn this depends on factors such as the choice of datatypes (relating to ALU capabilities) and compiler flags (for example, loop unrolling).
The performance of vector code running on a GPU is more difficult to quantify. As explained in this article, Rogue GPUs comprise a number of concurrent, multi-threaded processors. In this context, each work-item is executed by a single thread and has a scalar efficiency that can be defined similarly to code running on a scalar processor such as a CPU. However, in addition, there are also performance metrics related to utilization (how well memory latency is hidden as a result of the concurrent scheduling of multiple warps), occupancy (how easy it is for the multiprocessor to hide latency) and parallelism (to what extent threads in a warp execute in lock-step without diverging).
The figure below shows an example of three kernels executing on the GPU over time. Each kernel has an absolute execution time and, within a larger system, there may be delays between multiple executions of a kernel, for example representing the time taken for a CPU to prepare the next batch of data for processing. In addition to these absolute times, each kernel has the three efficiency metrics as mentioned above, which are discussed in more detail in the following subsections.
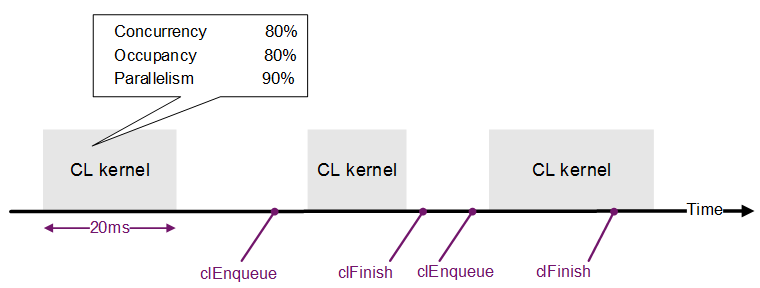
Rogue GPUs contain hardware counters that can be used to measure these performance metrics. These hardware counters are read by Imagination’s OpenCL development tools, allowing you to ‘see inside’ a kernel’s execution and gain a better understanding of any performance bottlenecks that can be eliminated. Once you have created the first implementation of your application, you should profile its performance to understand its performance and determine whether to invest more time in improving its performance. These tools include PVRTune, an OpenCL Occupancy Calculator and PVRShaderEditor.
Utilization
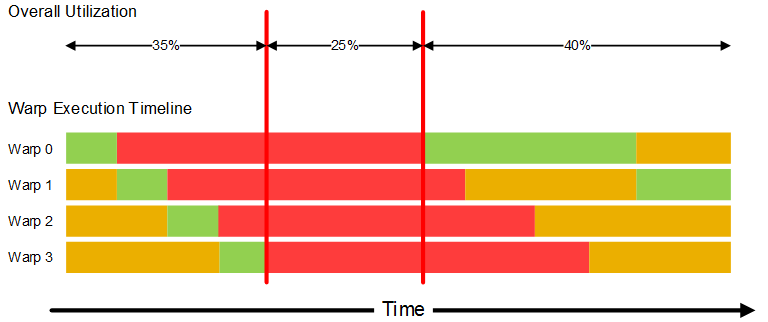
Multiprocessor utilization is the ratio of time spent by a multiprocessor executing its active warps versus the time that all warps are blocked. In the example below, all warps are blocked on memory operations for 25% of the execution time; the kernel’s utilization is 75%.
Occupancy
Multiprocessor occupancy is the ratio of resident warps to the total number of available residency slots. As discussed in full inside our OpenCL programming guidelines, the total number of available residency slots may be limited due to a kernel’s private and local memory requirements. Of these available slots, the total number actually used may be further limited by the speed at which the GPU can issue warps to the multiprocessors. The former metric can usually be calculated at compile-time, with the latter being determined at run-time.
The figure below shows an occupancy graph for a sample kernel, produced by Imagination’s OpenCL occupancy calculator tool. The purple triangle represents a specified workgroup size of 256, which the graph shows has a best-case occupancy of 16 warps (100%). The graph also shows the impact of varying the workgroup size, for example, reducing the workgroup size to 128 reduces occupancy to 8 warps (50%). This could be related to a workgroup’s memory requirements. For example, if the workgroup of size 256 allocates 2048 words from the common-store memory, which has a total capacity of 4096 words, then two workgroups can be held on a multiprocessor occupying 16 slots. If the workgroup size is reduced to 128, and assuming the same memory requirements, then two workgroup will allocate all of the available local memory thus occupying only 8 slots, and preventing the multiprocessor from accepting further warps for the other 8 slots.

Note that occupancy is not a direct measure of performance: a kernel that achieves 100% utilization with 50% occupancy is as efficient as a kernel that achieves 100% utilization with 100% occupancy. In the former situation it might even be desirable to double the amount of private memory available to each work-item, to further improve the scalar performance of the work-items.
Parallelism
Parallelism is the ratio of lock-step to serialized operations performed by the work-items; work-items usually execute in lock-step parallelism. If work-items in a warp diverge via a conditional branch, the hardware serializes execution of each divergent branch, disabling work-items not on that path, and when all paths complete the work-items converge back to the same execution path. These two types of execution are shown below:
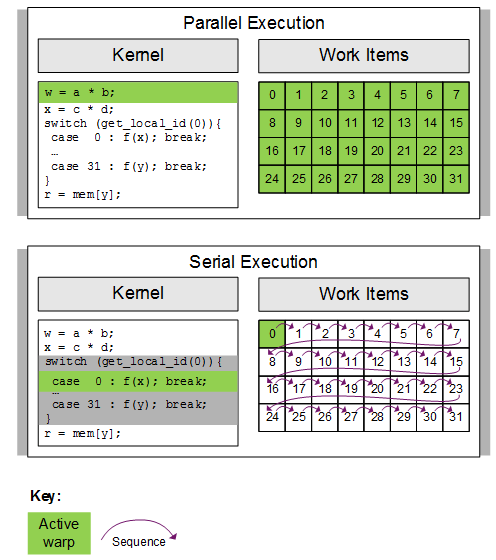
In the first case, all threads execute the statement in lock-step (100% parallel efficiency) but in the second statement all threads take turns executing the statement in sequence (0% parallel efficiency).
With the above metrics in mind, our OpenCL programming guidelines will give you more detail on how the Rogue GPU executes OpenCL programs, enabling you to apply even more advanced tuning techniques to improve performance.
Please let us know if you have any feedback on the materials published on the blog and leave a comment on what you’d like to see next. Make sure you also follow us on Twitter (@ImaginationTech) for more news and announcements from Imagination.



